

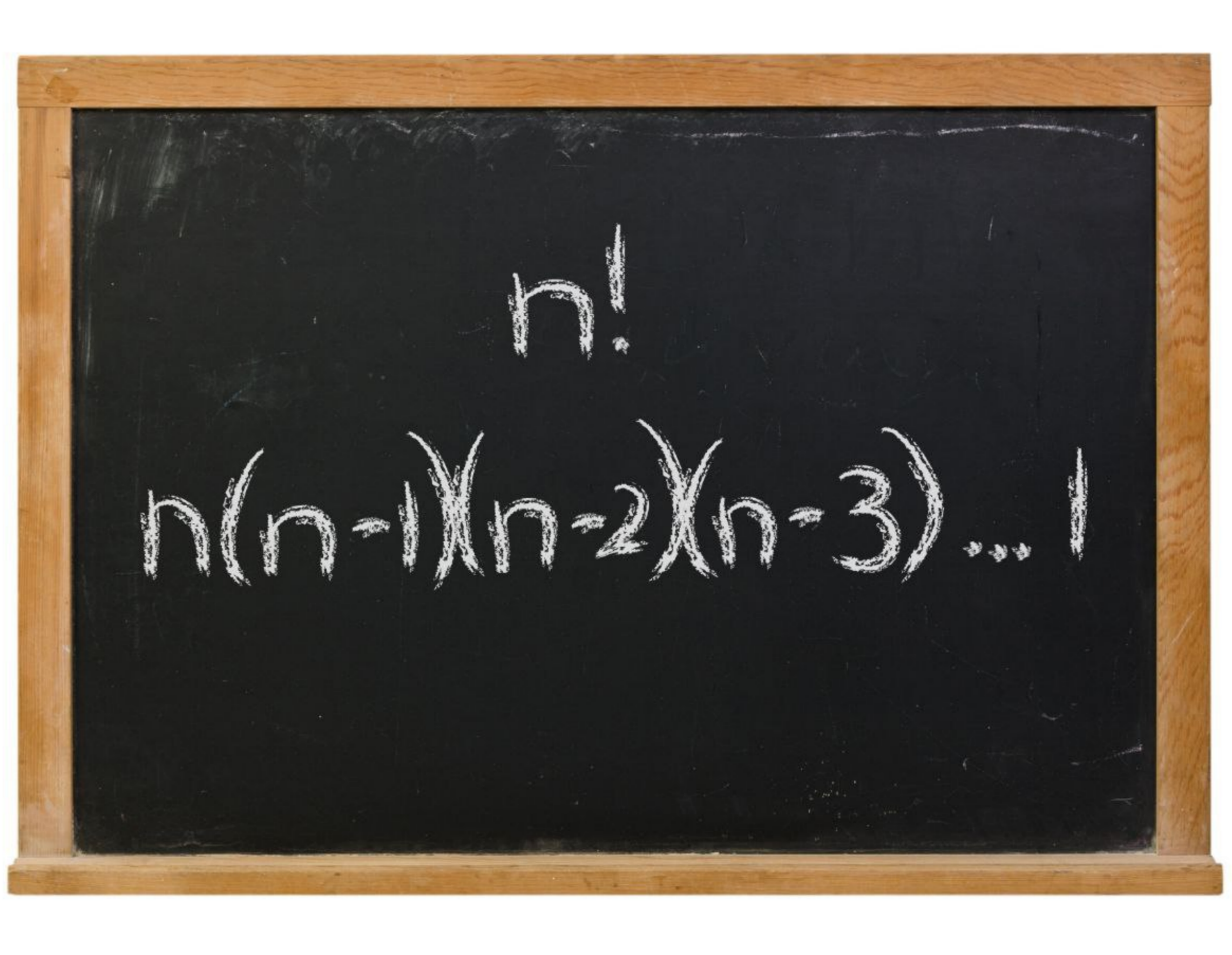
Permütasyon – Kombinasyon
2 Mayıs 2021
Ayağınız yerden kesilsin istiyorsunuz, ancak fiyatlar izin vermiyor. Sürekli sitelerden takip etme yerine bir kod yazalım mı? Kod sayfaya gitsin tüm fiyatları çeksin. Sonra siz, ister istatistiksel analiz yapın isterseniz fiyat belirsizliğini çıkarın 🙂 Evet veri (data) analizi için en önemli şey tabi ki önce analiz edilecek veriyi bulmak. İşte kod şurada:
import requests
from bs4 import BeautifulSoup as bs
adres = "https://www.araba.com/otomobil/audi"
baslik={"user-agent":"Mozilla/5.0 (X11; Linux x86_64; rv:98.0) Gecko/20100101 Firefox/98.0"}
sayfa = requests.get(adres, headers=baslik).text
soup = bs(sayfa, "lxml")
fiyatlar = soup.find_all("div",{"class":"prices"})
for fiyat in fiyatlar:
print(int(fiyat.text[:-3].replace(".","")))
Kodu hemen kopyalayın ve anında fiyatların nasıl geldiğini siz de görün. Şimdi biraz kodu değiştirin kafanıza göre ve değişikliklerin neler yaptığını görün, merak etmeyin orjinal kod burada çok bozarsanız yeniden buradan alabilirsiniz.
Şimdi gelelim bu işlemi nasıl yaptığımıza. İki kütüphane kullandık, requests ve bs4 kütüphanesi. requests web sayfasını (html olarak) indirmek için bs4 ise web sayfasından istediğimiz veriyi temizleyerek çekip almak için kullanacağımız kütüphane. Önce veri çekeceğimizi sayfanın adresini adres diye bir değişken oluşturarak eşitledik. Biz Audi marka arabanın fiyatına bakacağız, bunun için arabam.com adresine gidip Audi marka arabayı seçtik. hatta filtrelerimiz varsa ona göre hepsini belirledikten sonra, adres satırını kopyalayarak buraya yapıştırdık.
Biz pythonla siteden veri çekeceğiz. Bu bir tarayıcı değil (chrome, edge, firefox) o sebeple bazı siteler bunu engelliyorlar. Bunu atlayabilmek adına pythona bir tarayıcı gibi davranması için bir başlık ekleyeceğiz. Bu sebeple, 5. satırda başlık diye bir değişken oluşturduk ve buraya bir firefox tarayıcısıymış gibi davranması için eklemeler yaptık. Burayı değiştirmek isterseniz google’dan user agent examples ile arama yapıp başka tarayıcılar için gerekli metinleri bulabilirsiniz.
6. satırda sayfa diye bir değişken oluşturduk ve requests kütüphanesi aracılığı ile arabam.com‘daki Audi marka aracın web sayfasını indirdik. Buraya bir tarayıcıdan bağlanıyormuş gibi göstermek için headers ekledik ve bunu bir üst satırdaki baslik olarak tanımladık. Dikkat ederseniz satırın sonunda .text yazıyor. İndirdiğimiz sayfayı metine çevirdik. Nasıl bir şey olduğunu anlamak isterseniz Variable Explorer‘dan bakabilirsiniz ya da konsola sayfa yazarsanız karmaşık bir sürü yazılar olduğunu göreceksiniz. Bu aslında web sayfasına sağ tıklayıp kaynağını göster dediğimizde karşımıza çıkan html diliyle yazılmış web sayfası. Bunu temizlemek ve ihtiyacımız olan veriyi çekmek istiyoruz.
7. satırda bs4 kütüphanesine sayfayı tanıtıyoruz, ve bunun bir html sayfası olduğunu (bs4 için lxml) belirtiyoruz. Sonrası sayfadaki fiyatın nerede olduğunu bulmak. Bunun için tarayıcıdan( firefox, chrome) web sayfasını açıp sağ tıklıyoruz ve öğeyi inceleyi tıklıyoruz. Sonra açılan panelin sol üst köşesindeki fare simgesine basıp fiyatın üstününe geliyoruz. Karışık geldiyse şu resimdeki gibi olacak.
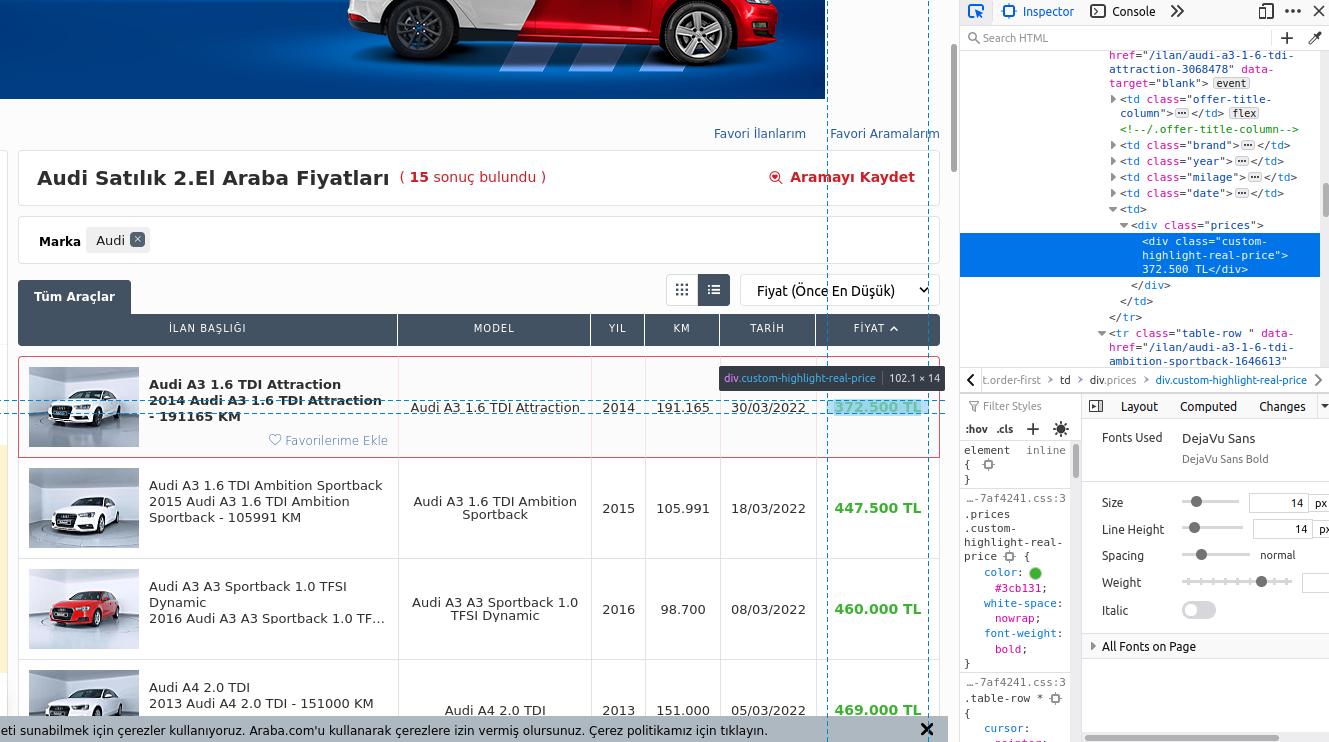
Gördüğünüz üzere mavi satırla seçili satır, fiyatın yazıldığı yeri gösteriyor html koduyla yazılmış sayfada. Burada bs4 kütüphanesinin bu veriyi bulacağı yeri not alıyoruz “div”, “class”, “prices”. İşte 7. satırda fiyatların hepsini alabilmek için .findAll ile not aldığımız konumu yazıyoruz buraya. Böylece sayfadaki tüm fiyatları almış oluyoruz.
Bu fiyatları tek tek göstermek için, çünkü bu haliyle bir liste formunda, for döngüsü kullanacağız. 9. satırda fiyat değişkenini fiyatlar listesinde döndürerek her bir fiyatı almak için döngüyü tanımlıyoruz. Son olarak 10. satırda her fiyatın html kodlarını temizlemek için .text komutu kullanıyoruz. Lütfen siz denerken .text‘den sonraki ifadeleri silin. Göreceksiniz ki fiyatın sonunda TL yazıyor. Bunu silmek ve sadece rakamları almak için [:-3] yazıyoruz. Yani baştan başla ve sondan 3. haneye kadar olan kısmı al. Bir sorunumuz daha var, sayının içinde “.” var ayraç olarak bunu silmek içinde .replace kullanarak “.”yı değiştiriyoruz. Son olarak da bu bir metin (string) bunu int() fonksiyonuyla sayıya (integer) dönüştürüyoruz.
Bu arada, aynı sayfa için kodunuzu sürekli çalıştırırsanız, site bir saldırır altında olduğu zannıyla engelleyecektir sizi. Eğer sayfa değişkeniniz “too many request!” şeklinde oluşuyorsa, lütfen başka bir user-agent ya da adres deneyerek ilerleyebilirsiniz. Yukarıdaki anlatımlar biraz karışık gelebilir, yılmayın hemen bir haber sitesinden haber çekin, ya da bu sitenin ana sayfasındaki blog başlıklarını çekin. Bir kaç deneme sonra mantığını kavrayacaksınız. Son not: Bazı siteler bu veri çekme işlemini engellemek için farklı kodlar kullanıyorlar, bunları aşmanın yolları var ama bu yazı sadece sizi giriş aşamasına hazırlamak için hazırlandı. Sizi taze elde ettiğiniz verilerle baş başa bırakayım ben.


{kind=link}
{kind=link}
2 Comments
Hocam merhabalar. Bu yazıyı görünce buna benzeyen çok merak ettiğim bir konuyu sormak istiyorum. Özellikle organizasyonlarda uçuş tarihleri ve zamanlarını excel listesine alıp planlama yapmak istiyoruz. Bu durumda uçuş bilgilerini toplu gösteren bir siteden ya da farkı havayolu sitelerinden excel’e almanın bir yolu var mıdır acaba?
Merhaba Eray,
Veriyi siz görebiliyorsanız, almanın da bir yolu vardır. Burada anlatılan gibi sitenin html kodundan ayıklanamayan veriler için, belki sizin için selenium kütüphanesi oldukça kullanışlı olabilir. Bu sitenin amacı üzüm vermek değil, balık tutmayı öğretmek.
Selamlar,